Or try one of the following: 詹姆斯.com, adult swim, Afterdawn, Ajaxian, Andy Budd, Ask a Ninja, AtomEnabled.org, BBC News, BBC Arabic, BBC China, BBC Russia, Brent Simmons, Channel Frederator, CNN, Digg, Diggnation, Flickr, Google News, Google Video, Harvard Law, Hebrew Language, InfoWorld, iTunes, Japanese Language, Korean Language, mir.aculo.us, Movie Trailers, Newspond, Nick Bradbury, OK/Cancel, OS News, Phil Ringnalda, Photoshop Videocast, reddit, Romanian Language, Russian Language, Ryan Parman, Traditional Chinese Language, Technorati, Tim Bray, TUAW, TVgasm, UNEASYsilence, Web 2.0 Show, Windows Vista Blog, XKCD, Yahoo! News, You Tube, Zeldman
ongoing by Tim Bray
ongoing fragmented essay by Tim BrayQRS: Epsilon Wrangling 7 Jul 2025, 7:00 pm
I haven’t shipped any new features for Quamina in many months, partly due to a flow of real-life distractions, but also I’m up against tough performance problems in implementing Regular Expressions at massive scale. I’m still looking for a breakthrough, but have learned things about building and executing finite automata that I think are worth sharing. This piece has to do with epsilons; anyone who has studied finite automata will know about them already, but I’ll offer background for those people to skip.
I’ve written about this before in
Epsilon Love. A commenter pointed out that the definition of “epsilon”
in that piece is not quite right per standard finite-automata theory, but it’s still a useful in that it describes how
epsilons support constructs like the shell-style “*”.
Background
Finite automata come in two flavors: Deterministic (DFA) and Nondeterministic (NFA). DFAs move from state to state one input symbol at a time: it’s simple and easy to understand and to implement. NFAs have two distinguishing characteristics: First, when you’re in a state and an input symbol arrives, you can transfer to more than one other state. Second, a state can have “epsilon transitions” (let’s say “ε” for epsilon), which can happen any time at all while you’re in that state, input or no input.
NFAs are more complicated to traverse (will discuss below) but you need them if you want to
implement regular expressions with . and ? and * and so on. You can turn any NFA into a
DFA, and I’ll come back to that subject in a future piece.
For implementing NFAs, I’ve been using Thompson's construction, where “Thompson” is Ken Thompson, co-parent of Unix. This technique is also nicely described by Russ Cox in Regular Expression Matching Can Be Simple And Fast. You don’t need to learn it to understand this piece, but I’ll justify design choices by saying “per Thompson”.
I’m going to discuss two specific issues today, ε-closures and a simpler NFA definition.
ε-closures
To set the stage, consider this regexp: A?B?C?X
It should match “X” and “BX” and “ACX” and so on, but not “CAX” or “XX”.
Thompson says that you implement A? with a
transition to the next state on “A” and another ε-transition to that next state; because if you see an “A” you should transition,
but then you can transition anyhow even if you don’t.
The resulting NFA looks like this:
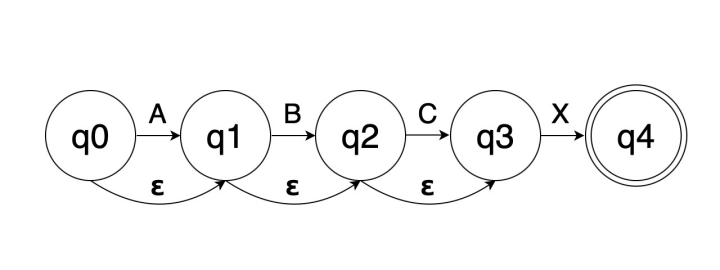
In finite-automaton
math, states are usually represented by the letter “q” followed by a number (usually italicized and subscripted, like
q0, but not here, sorry). Note q4’s double circle which means it’s
a goal state, i.e. if we get here we’ve matched the regexp.
I should add that this was produced with
draw.io, which seems to make this sort of thing easy.
Back to that NFA
So, here’s a challenge: Sketch out the traversal code in your head. Think about the input strings “AX” and “BCX” and just “X” and how you’d get through the NFA to the Q4 goal state.
The trick is what’s called the ε-closure. When you get to a state, before you look at the next input symbol, you have to set
up to process it. In this case, you need to be able to transition on an A or B or C. So what you do is pull together the
start state q0 and also any other states you can reach from there through ε-transitions. In this case, the ε-closure
for the start state is {q0, q1, q2, q3}.
Suppose, then, that you see a “B” input symbol. You apply it to all the states in the ε-closure. Only q1 matches,
transitioning you to
q2. Before you look at the next input symbol, you compute the ε-closure for q2, which turns
out to be {q2, q3}. With this ε-closure, you can match “C” or “X”. If you get a “C”, you”ll step to
q3, whose ε-closure is just itself, because “X” is the only path forward.
So your NFA-traversal algorithm for one step becomes something like:
Start with a list of states.
Compute the ε-closure of that list.
Read an input symbol.
For each state in the ε-closure, see if you can traverse to another state.
If so, add it to your output list of states.
When you’re done, your output list of states is the input to this algorithm for the next step.
Computation issues
Suppose your regular expression is (A+BC?)+. I’m not going to sketch out the NFA, but just looking at it tells
you that it has to have loopbacks; once you’ve matched the parenthetized chunk you need to go back to a state where you can
recognize another occurrence.
For this regexp’s NFA, computing the ε-closures can lead you into an infinite loop. (Should be obvious, but I didn’t realize it until
after the first time it happened.)
You can have loops and you can also have dupes. In practice, it’s not that uncommon for a state to have more than one ε-transition, and for the targets of these transitions to overlap.
So you need to watch for loops and to dedupe your output. I think the only way to avoid this is with a cookie-crumbs “where I’ve been” trail, either as a list or a hash table.
Both of these are problematic because they require allocating memory, and that’s something you really don’t want to do when you’re trying to match patterns to events at Quamina’s historic rate of millions per second.
I’ll dig into this problem in a future Quamina-Diary outing, but obviously, caching computed epsilon closures would avoid re-doing this computation.
Anyhow, bear ε-closures in mind, because they’ll keep coming up as this series goes on.
And finally, simplifying “NFA”
At the top of this piece, I offered the standard definition of NFAs: First, when you’re in a state and an input symbol arrives, you can transfer to more than one other state. Second, you can have ε-transitions. Based on my recent work, I think this definition is redundant. Because if you need to transfer to two different states on some input symbol, you can do that with ε-transitions.
Here’s a mini-NFA that transfers from state q0 on “A” to both q1 and q2.
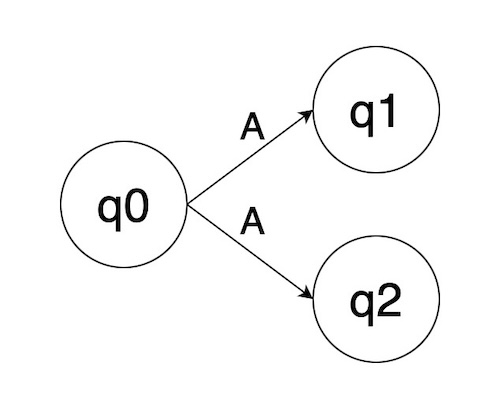
And here’s how you can achieve the same effect with ε-transitions:
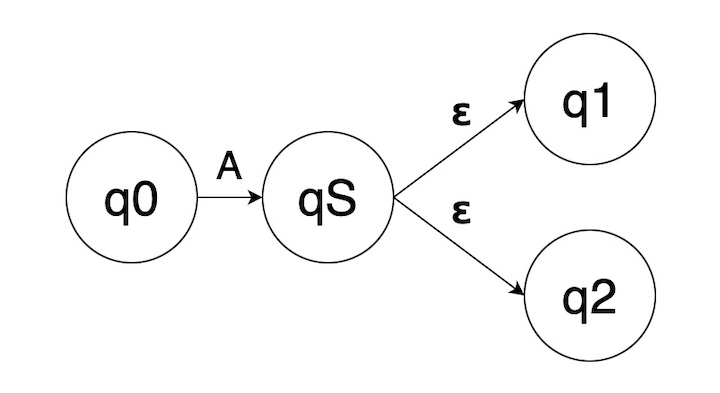
In that NFA, in qS the “S” stands for “splice”, because it’s a state that exists to connect
two threads of finite-automaton traversal.
I’m pretty sure that this is more than just a mathematical equivalence. In my regexp implementation, so far at least,
I’ve never encountered a need to do that first kind of dual transition. Furthermore, the “splice” structure is how Thompson
implements the regular-expression “|” operator.
So if you’re building an NFA, all the traversal stuff you need in a state is a simple map from input symbol to next state, and a list of ε-transitions.
Next up
How my own implementation of NFA traversal collided head-on into the Benchmark From Hell and still hasn’t recovered.
The Real GenAI Issue 6 Jul 2025, 7:00 pm
Last week I published a featherweight narrative about applying GenAI in a real-world context, to a tiny programming problem. Now I’m regretting that piece because I totally ignored the two central issues with AI: What it’s meant to do, and how much it really costs.
What genAI is for
The most important fact about genAI in the real world is that there’ve been literally hundreds of billions of dollars invested in it; that link is just startups, and ignores a comparable torrent of cash pouring out of Big Tech.
The business leaders pumping all this money of course don’t understand the technology. They’re doing this for exactly one reason: They think they can discard armies of employees and replace them with LLM services, at the cost of shipping shittier products. Do you think your management would spend that kind of money to help you with a quicker first draft or a summarized inbox?
Adobe said the quiet part out loud: Skip the Photoshoot.
At this point someone will point out that previous technology waves have generated as much employment as they’ve eliminated. Maybe so, but that’s not what business leaders think they’re buying. They think they’re buying smaller payrolls.
Maybe I’m overly sensitive, but thinking about these truths leads to a mental stench that makes me want to stay away from it.
How much does genAI cost?
Well, I already mentioned all those hundreds of billions. But that’s pocket change. The investment community in general and Venture Capital in particular will whine and moan, but the people who are losing the money are people who can afford to.
The first real cost is hypothetical: What if those business leaders are correct and they can gleefully dispose of millions of employees? If you think we’re already suffering from egregious levels of inequality, what happens when a big chunk of the middle class suddenly becomes professionally superfluous? I’m no economist so I’ll stop there, but you don’t have to be a rocket scientist to predict severe economic pain.
Then there’s the other thing that nobody talks about, the massive greenhouse-gas load that all those data centers are going to be pumping out. This at a time when we we blow past one atmospheric-carbon metric after another and David Suzuki says the fight against climate change is lost, that we need to hunker down and work on survival at the local level.
The real problem
It’s the people who are pushing it. Their business goals are quite likely, as a side-effect, to make the world a worse place, and they don’t give a fuck. Their technology will inevitably worsen the onrushing climate catastrophe, and they don’t give a fuck.
It’s probably not as simple as “They’re just shitty people” — it’s not exactly easy to escape the exigencies of modern capitalism. But they are people who are doing shitty things.
Is genAI useful?
Sorry, I’m having trouble even thinking about that now.
My First GenAI Code 1 Jul 2025, 7:00 pm
At the moment, we have no idea what the impact of genAI on software development is going to be. The impact of anything on coding is hard to measure systematically, so we rely on anecdata and the community’s eventual consensus. So, here’s my anecdata. Tl;dr: The AI was not useless.
The problem
My current work on Quamina involves dealing with collections of finite-automata states, which, in the Go programming language, are represented as slices of pointers to state instances:
[]*faState
The problem I was facing was deduping them, so that there would be only one instance corresponding to any particular
collection. This is what, in Java, the intern() call does with strings.
The algorithm isn’t rocket science:
Dedupe the states, i.e. turn the collection into a set.
For each set of states, generate a key.
Keep a hash table of sets around, and use the key to see whether you’ve already got such a set, and if so return it. Otherwise, make a new entry in the hash table and return that.
I’m out of touch with the undergrad CS curriculum, but this feels like a second-year assignment or thereabouts? Third?
Enter Claude
So I prompted Claude thus:
I need Go code to provide a "intern"-like function for lists of pointers. For example, if I have several different []*int arrays, which may contain duplicates, I want to call intern() on each of them and get back a single canonical pointer which is de-duplicated and thus a set.
Claude did pretty well. It got the algorithm right, the code was idiomatic and usefully commented, and it also provided a
decent unit test (but in a main() stanza rather than a proper Go test file).
I didn’t try actually running it.
The interesting part was the key computation. I, being lazy, had just done a Go fmt.Sprintf("%p")
incantation to get a hex string representing each state’s address, sorted them, joined them, and that was the key.
Claude worked with the pointers more directly.
// Sort by pointer address for consistent ordering
sort.Slice(unique, func(i, j int) bool {
return uintptr(unsafe.Pointer(unique[i])) < uintptr(unsafe.Pointer(unique[j]))
})Then it concatenated the raw bytes of the map addresses and lied to Go by claiming it was a string.
// Create key from pointer addresses
key := make([]byte, 0, len(slice)*8)
for _, ptr := range slice {
addr := uintptr(unsafe.Pointer(ptr))
// Convert address to bytes
for i := 0; i < 8; i++ {
key = append(key, byte(addr>>(i*8)))
}
}
return string(key)This is an improvement in that the keys will be half the size of my string version. I didn’t copy-paste Claude’s code wholesale, just replaced ten or so lines of key construction.
Take-away
I dunno. I thought the quality of the code was fine, wouldn’t have decomposed the functions in the same way but wouldn’t have objected on review. I was pleased with the algorithm, but then I would be since it was the same one I’d written, and, having said that, quite possibly that’s the only algorithm that anyone has used. It will be super interesting if someone responds to this write-up saying “You and Claude are fools, here’s a much better way.”
Was it worth fifteen minutes of my time to ask Claude and get a slightly better key computation? Only if this ever turns out to be a hot code path and I don’t think anybody’s smart enough to know that in advance.
Would I have saved time by asking Claude first? Tough to tell; Quamina’s data structures are a bit non-obvious and I would have had to go to a lot of prompting work to get it to emit code I could use directly. Also, since Quamina is low-level performance-critical infrastructure code, I’d be nervous about having any volume of code that I didn’t really really understand.
I guess my take-away was that in this case, Claude knew the Go idioms and APIs better than I did; I’d never looked at the unsafe package.
Which reinforces my suspicion that genAI is going to be especially useful at helping generate code to talk to big complicated APIs that are hard to remember all of. Here’s an example: Any moderately competent Android developer could add a feature to an app where it strobes the flash and surges the vibration in sync with how fast you’re shaking the device back and forth, probably in an afternoon. But it would require a couple of dozen calls into the dense forest of Android APIs, and I suspect a genAI might get you there a lot faster by just filling the calls in as prompted.
Reminder: This is just anecdata.
Qobuz and Mac 22 Jun 2025, 7:00 pm
Back in March I offered Latest Music (feat. Qobuz), describing all the ways I listen to music (Tl;dr: YouTube Music, Plex, Qobuz, record player). I stand by my opinions there but wanted to write more on two subjects: First Qobuz, because it suddenly got a lot better. And a recommendation, for people with fancy A/V setups, that you include a cheap Mac Mini.
Qobuz
That other piece had a list of the reasons to use Qobuz, but times have changed, so let’s revise it:
It pays artists more per stream than any other service, by a wide margin.
It seems to have as much music as anyone else.
It’s album-oriented, and I appreciate artists curating their own music.
Classical music is a first-class citizen.
It’s actively curated; they highlight new music regularly, and pick a “record of the week”. To get a feel, check out Qobuz Magazine; you don’t have to be a subscriber.
It gives evidence of being built by people who love music.
They’re obsessive about sound quality, which is great, but only makes a difference if you’re listening through quality speakers.
A few weeks ago, the mobile app quality switched from adequate to excellent.
That app
I want to side-trip a bit here, starting with a question. How long has it been since an app you use has added a feature that was genuinely excellent and let you do stuff you couldn’t before and didn’t get in your way and created no suspicion that it was strip-mining your life for profit? I’m here to tell you that this can still happen, and it’s a crushing criticism of my profession that it so rarely does.
I’m talking about Qobuz Connect. I believe there are other music apps that can do this sort of stuff, but it feels like magic to me.
It’s like this. I listen to music at home on an audiophile system with big speakers, in our car, and on our boat. The only app I touch is the Qobuz Android app. The only time it’s actually receiving and playing the music itself is in the car, with the help of Android Auto. In the other scenarios it’s talking to Qobuz running on a Mac, which actually fetches the music and routes it to the audio system. Usually it figures out what player I want it to control automatically, although there’ve been a couple times when I drove away in the car and it got confused about where to send the music. Generally, it works great.
The app’s music experience is rich and involving.
It has New Releases and curated playlists and a personalized stream for me and a competent search function for those times I absolutely must listen to Deep Purple or Hania Rani or whoever.
I get a chatty not-too-long email from Qobuz every Friday, plugging a few of the week’s new releases, with sideways and backward looks too. (This week: A Brian Wilson stream.) The app has so much stuff, especially among the themed streams, that I sometimes get lost. But somehow it’s not irritating; what’s on the screen remains musically interesting and you can always hit the app’s Home button.
Qobuz has its own musical tastes that guide its curation. They’re not always compatible with mine — my tolerance for EDM and mainstream Hip-hop remains low. And I wish they were stronger on Americana. But the intersection is broad enough to provide plenty of enjoyable new-artist experiences. Let me share one with you: Kwashibu Area Band, from Ghana.
Oh, one complaint: Qobuz was eating my Pixel’s battery. So I poked around online and it’s a known problem; you have to use the Android preferences to stop it from running in the background. Huh? What was it doing in the background anyhow?! But it seems to work fine even when it’s not doing it.
A Mac, you say?
The music you’re listening to is going to be stored on disk, or incoming from a streaming service. Maybe you want to serve some of the stored music out to listen to it in the car or wherever. There are a variety of audio products in the “Streamer” category that do some of these things in various combinations. A lot of them make fanciful claims about the technology inside and are thus expensive, you can easily spend thousands.
But any reasonably modern computer can do all these things and more, plus it also can drive a big-screen display, plus it will probably run the software behind whatever next year’s New Audio Hotness is.
At this point the harder-core geeks will adopt a superior tone of voice to say “I do all that stuff with FreeBSD and a bunch of open-source packages running on a potato!”
More power to ’em. But I recommend a basic Apple Silicon based Mac Mini, M1 is fine, which you can get for like $300 used on eBay. And if you own a lot of music and video you can plug in a 5T USB drive for a few more peanuts. This will run Plex and Qobuz and almost any other imaginable streaming software. Plus you can plug it into your home-theater screen and it has a modern Web browser so you can also play anything from anywhere on the Web.
I’ve been doing this for a while but I had one big gripe. When I wanted to stream music from the Mac, I needed to use a keyboard and mouse, so I keep one of each, Bluetooth-flavored, nearby. But since I got Qobuz running that’s become a very rare occurrence.
You’re forgetting something
Oh, and yeah, there’s the record player. Playing it requires essentially no software at all, isn’t that great?
Long Links 21 Jun 2025, 7:00 pm
“Wow, Tim, didn’t you do a Long Links just last month? Been spending too much time doomscrolling, have we?” Maybe. There sure are a lot of tabs jostling each other along the top of that browser. Many are hosting works that are both long and good. So here they are; you probably don’t have time for all of ’em but my hope is that one or two might reward your visit.
Let’s start with a really important subject: Population growth oh actually these days it’s population shrinkage. For a short-sharp-shock-flavored introduction I recommend South Korea Is Over which explains the brick wall societies with fertility rates way below the replacement rate of 2.1 children per woman per lifetime are hurtling toward. South Korea, of course, being the canonical example. But also Japan and Taiwan and Italy and Spain and so on.
And, of course, the USA, where the numbers aren’t that much higher: U.S. Fertility Rate (1950-2025). Even so, the population still grows (because of immigration), albeit at less than 1% per annum: U.S. Population Growth Rate. If the MAGAs get their way and eventually stop all non-white immigration, the US will be in South Korea territory within a generation or two.
A reasonable person might ask why. It’s not really complicated, as you can read here: A Bold Idea to Raise the Birthrate: Make Parenting Less Torturous. From which I quote: “To date, no government policies have significantly improved their nation’s birthrates for a sustained period.” The essay argues convincingly that it’s down to two problems: Capitalism and sexism. Neither of which offers an easy fix.
Speaking of the travails of late capitalism, here’s how bad it’s getting: America Is Pushing Its Workers Into Homelessness.
For a refreshingly different take on the business world, here’s Avery Pennarun, CEO of Tailscale: The evasive evitability of enshittification. Not sure I buy what he’s saying, but still worth reading.
Most people who visit these pages are geeks or geek-adjacent. If you’re one of those, and especially if you enjoy the small but vibrant genre of Comical Tech War Stories, I recommend Lock-Free Rust: How to Build a Rollercoaster While It’s on Fire
And here’s write-up on an AWS product which has one of the best explanations I’ve ever read of the different flavors modern databases come in: Introduction to the Fundamentals of Amazon Redshift
Of course, the geek conversation these days is much taken up with the the impact of genAI as in “vibe coding”. To summarize the conversation: A few people, not obviously fools, are saying “This stuff seems to help me” and many others, also apparently sensible, are shouting back “You’re lying to yourself, it can’t be helping!” Here is some of the testimony: Kellan on Vibe coding for teams, thoughts to date, Armin Ronacher on Agentic Coding Recommendations, Harper on Basic Claude Code, and Klabnik on A tale of two Claudes
I lean to believing narratives of personal experience, but on the other hand the skeptics make good points. Another random piece of evidence: Because I’m lazy, I tend to resist adopting technologies that have steep learning curves, which genAI currently does. On many occasions, this has worked out well because those technologies have turned out not to pay off very well. Am I a canary in the coal mine?
*cough*
Since I introduced myself into the narrative, I’ll note that today is my 70th birthday. I am told that this means that my wisdom has now been maximized, so you’re safe in believing whatever you read in this space. I don’t have anything special to say to commemorate the occasion, so here’s a picture of my neighborhood’s network infrastructure, which outlines the form of a cathedral’s nave. I’m sure there’s a powerful metaphor lurking in there.

Oh, and here’s a photography Long Link: What is HDR, anyway? It’s actually a pitch for a nice-looking mobile camera app, but it offers real value on things that can affect the quality of your pictures.
Regular readers will know that I’m fascinated by the many unsolved issues and open questions in cosmology, which are by definition the largest problems facing human consciousness. The ΛCDM-vs-MOND controversy, i.e. “Is there really dark matter or does gravity get weird starting at the outer edges of galaxies?”, offers great entertainment value. And, there is news!
First of all, here’s a nice overview on the controversy: Modified Newtonian Dynamics: Observational Successes and Failures.
Which points out that the behavior of “wide binary” star systems ought to help resolve the issue, but that people who study it keep coming up with contradictory findings. Here’s the latest, from Korean researchers: Press release New method of measuring gravity with 3D velocities of wide binary stars is developed and confirms modified gravity and peer-reviewed paper: Low-acceleration Gravitational Anomaly from Bayesian 3D Modeling of Wide Binary Orbits: Methodology and Results with Gaia Data Release 3. Spoiler: They think the gravity gets weird. I have a math degree but cosmology math is generally way over my head. Having said that, I think those South Koreans may be a bit out over their skis; I generally distrust heroic statistical methods. We’ll see.
Let’s do politics. It turns out that the barbaric junta which oppresses the people of China does not limit its barbarism to its own geography: Followed, threatened and smeared — attacks by China against its critics in Canada are on the rise.
More politics: The MAGAs are always railing against “elites”. Here are two discussions of what they mean: What the Comfort Class Doesn’t Get and When They Say Elites, They Mean Us.
The world’s biggest political issue should be the onrushing climate crisis. When Trump and his toadies are justly condemned and ridiculed by future historians, it is their malevolent cluelessness on this subject that may burn the hottest. Who knows, maybe they’ll pay attention to this: Insurers Want Businesses to Wake Up to Costs of Extreme Heat.
The list of Long Links is too long
So I’ll try to end cheerfully.
A graceful essay about an old camera and a dreamy picture: A Bridge Across Time: For Sebastião Salgado
Latin Wikipedia has 140,000 articles; consider the delightful discussion of Equus asinus.

Asinus in opere tesselato Byzantino
Here’s a lovely little song from TORRES and Julien Baker: The Only Marble I’ve Got Left.
Finally, a clear-eyed if lengthy essay on why and how to think: Should You Question Everything?
June 2025 C2PA News 17 Jun 2025, 7:00 pm
Things are happening in the C2PA world; here are a couple of useful steps forward, plus cheers and boos for Adobe. Plus a live working C2PA demo you can try out.
Refresher: The C2PA technology is driven by the Content Authenticity Initiative and usually marketed as “Content Credentials”. I’ve written before about it, an introduction in 2023 and a progress report last October.
Let’s start with a picture.

I was standing with the camera by the ocean at dusk and accidentally left it in the “B” long-exposure setting, so this isn’t really a picture of anything but I thought it was kinda pretty.
Validating Content Credentials
As I write this, there are now at least two C2PA-validator Chrome extensions: the ContentLens C2PA Validator from ContentLens and C2PA Content Credentials from Digimarc.
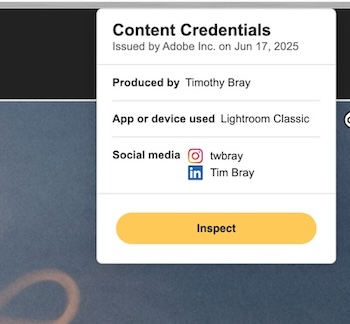
If you install either of them, and then you click on that picture just above in Chrome to get the larger version, then you right-click on the larger picture, the menu will offer Content-Credentials validation.
Doing this will produce a little “CR” logo at the top right corner, meaning that the C2PA data has been verified as being present and signed by a trusted certificate issuer, in this case Adobe.
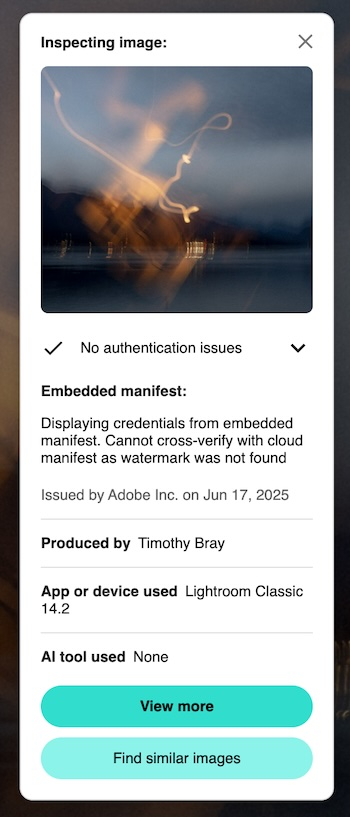
Then there’s a popup; the two extensions’ are on the right. They’re different, in interesting ways. Let’s walk through the second one.
The little thumbnail at the top of the popup is what the image looked like when the C2PA was added. Not provided by the other verifier.
The paragraph beginning “Displaying credentials…” says that the C2PA manifest was embedded in the JPG as opposed to stored out on the cloud; The cloud works fine, and is perhaps a good idea because the C2PA manifest can be quite large. I’m not clear on what the “watermark” is about.
“Issued by Adobe” means that the Chrome extension verified the embedded C2PA against Adobe’s public key and can be confident that yes, this was really signed by them.
“Produced by Timothy Bray” is interesting. How can it know? Well, it turns out that it used LinkedIn’s API to verify that I am timbraysoftwareguy over on LinkedIn. But it goes further; LinkedIn has an integration with Clear, the airport-oriented identity provider. To get a Clear account you have to upload government-issued ID, it’s not trivial.
So this short sentence expands to (take a deep breath) “The validator extension verified that Adobe said that LinkedIn said that Clear said that the government ID of the person who posted this says that he’s named Timothy Bray.”
Note that the first extension’s popup also tells you that Adobe has verified what my LinkedIn and Instagram accounts are. This seems super-useful and I wonder why the other omits it.
“App or device used…” is simple enough, but I’m not actually sure how it works; I guess Adobe has embedded a keypair in my Lightroom installation? If I’d taken the picture with a C2PA-equipped camera this is where that history would be displayed.
“AI tool used None”. Interesting and useful, since Adobe provides plenty of genAI-powered tools. Of course, this relies on Lightroom telling the truth, but still.
The “View More” button doesn’t currently work; it takes you to the interactive contentcredentials.org/verify page, which seems to fail in retrieving the JPG. If you download the picture then upload it into the verify page (go ahead, it’s free) that seems to work fine. In addition to the info on the popup, the verify page will tell you (nontechically i.e. vaguely) what I did to the picture with Lightroom.
What’s good about this?
Well, it’s here and it works! There’s all this hype about how cool it will be when the C2PA includes info about what model of camera and lens it used and what the shutter speed was and so on, but eh, who cares really? What matters to me (and should matter to the world) is provenance: Who posted this thing?
As I write this, supporters of Israel and Iran are having an AI Slop Fight with fake war photos and videos. In a C2PA-rich world, you could check; If some clip doesn’t have Content Credentials you should probably be suspicious, and if it does, it matters whether it was uploaded by someone at IDF.il versus BBC.co.uk.
What’s wrong with this?
Look, I hate to nitpick. I’m overwhelmingly positive on this news, it’s an existence proof that C2PA can be made to work in the wild. My impression is that most of the money and muscle comes from Adobe; good on ’em. But there are things that would make it more useful, and usable by more Web sites. These are not listed in any particular order.
Identity!
Adobe, it’s nice that you let me establish my identity with LinkedIn, Instagram, and Clear. But what I’d really like is if you could also verify and sign my Fediverse and Bluesky handles. And, Fediverse and ATProto developers, would you please, first of all, stop stripping C2PA manifests from uploaded photo EXIF, and secondly, add your own link to the C2PA chain saying something like “Originally posted by @timbray@cosocial.ca.”
Because having verifiable media provenance in the world of social media would be a strong tool against disinformation and slop.
Oh, and another note to Adobe: When I export a photo, the embed-manifest also offers me the opportunity, under the heading “Web3”, to allow the image “be used for NFT creative attribution on supported marketplaces” where the supported marketplaces are Phantom and MetaMask. Seriously, folks, in 2025? Please get this scammy cryptoslime out of my face.
Browsers please…
This was done with Chrome extensions. There are people working on extensions for Firefox and Safari, but they’re not here yet. Annoyingly, the extensions also don’t seem to work in mobile Chrome, which is where most people look at most media.
I would love it if this were done directly and automatically by the browser. The major browsers aren’t perfect, but their creators are known to take security seriously, and I’d be much happier trusting one of them, rather than an extension from a company I’d never previously heard of.
… or maybe JavaScript?
The next-best solution would be a nice JS package that just Does The Right Thing. It should work like the way I do fonts: If you look in the source for the page you are now reading, the splodge of JS at the top includes a couple of lines that mention “typekit.com”. Typekit (since acquired by Adobe) offers access to a huge selection of excellent fonts. Those JS invocations result in the text you are now reading being displayed in FF Tisa Web Pro.
Which — this is important — is not free. And to be clear, I am willing to pay to get Content Credentials for the pictures on this blog. It feels exactly like paying a small fee for access to a professionally-managed font library. Operating a Content-Credentials service wouldn’t be free, it’d require running a server and wrangling certs. At scale, though, it should be pretty cheap.
So here’s an offer: If someone launches a service that allows me to straightforwardly include the fact that this picture was sourced from tbray.org in my Content Credentials, my wallet is (modestly) open.
By the way, the core JavaScript code is already under construction; here’s Microsoft and the Content Authority Initiative itself. There’s also a Rust crate for server-side use, and a “c2patool” command-line utility based on it..
Open-Source issues
You’ll notice that the right-click-for-Content-Credentials doesn’t work on the smaller version of the picture embedded in the text you are now reading; just the larger one. This is because the decades-old Perl-based ongoing publishing software runs the main-page pictures through ImageMagick, which doesn’t do C2PA. I should find a way to route around this.
In fact, it wouldn’t be rocket science for ImageMagick (or open-source packages generally) to write C2PA manifests and insert them in the media files they create. But how should they sign them? As noted, that requires a server that provides cert-based signatures, something that nobody would expect from even well-maintained open-source packages.
I dunno, maybe someone should provide a managed-ImageMagick service that (for a small fee) offers signed-C2PA-manifest embedding?
What’s next?
The work that needs to be done is nontrivial but, frankly, not that taxing. And the rewards would be high. Because it feels like a no-brainer that knowing who posted something is a big deal. Also the inverse: Knowing that you don’t know who posted it.
Where is it an especially big deal? On social media, obviously. It’s really time for those guys to start climbing on board.
AI Angst 6 Jun 2025, 7:00 pm
My input stream is full of it: Fear and loathing and cheerleading and prognosticating on what generative AI means and whether it’s Good or Bad and what we should be doing. All the channels: Blogs and peer-reviewed papers and social-media posts and business-news stories. So there’s lots of AI angst out there, but this is mine. I think the following is a bit unique because it focuses on cost, working backward from there. As for the genAI tech itself, I guess I’m a moderate; there is a there there, it’s not all slop. But first…
The rent is too damn high
I promise I’ll talk about genAI applications but let’s start with money. Lots of money, big numbers! For example, venture-cap startup money pouring into AI, which as of now apparently adds up to $306 billion. And that’s just startups; Among the giants, Google alone apparently plans $75B in capital expenditure on AI infrastructure, and they represent maybe a quarter at most of cloud capex. You think those are big numbers? McKinsey offers The cost of compute: A $7 trillion race to scale data centers.
Obviously, lots of people are wondering when and where the revenue will be to pay for it all. There’s one thing we know for sure: The pro-genAI voices are fueled by hundreds of billions of dollars worth of fear and desire; fear that it’ll never pay off and desire for a piece of the money. Can you begin to imagine the pressure for revenue that investors and executives and middle managers are under?
Here’s an example of the kind of debate that ensues.
“MCP” is
Model Context Protocol, used for communicating between LLM
software and other systems and services.
I have no opinion as to its quality or utility.
I suggest that when you’re getting a pitch for genAI technology, you should have that greed and fear in the back of your mind. Or maybe at the front.
And that’s just the money
For some reason, I don’t hear much any more about the environmental cost of genAI, the gigatons of carbon pouring out of the system, imperilling my children’s future. Let’s please not ignore that; let’s read things like Data Center Energy Needs Could Upend Power Grids and Threaten the Climate and let’s make sure every freaking conversation about genAI acknowledges this grievous cost.
Now let’s look at a few sectors where genAI is said to be a big deal: Coding, teaching, and professional communication. To keep things balanced, I’ll start in a space where I have kind things to say.
Coding
Wow, is my tribe ever melting down. The pro- and anti-genAI factions are hurling polemical thunderbolts at each other, and I mean extra hot and pointy ones. For example, here are 5600 words entitled I Think I’m Done Thinking About genAI For Now. Well-written words, too.
But, while I have a lot of sympathy for the contras and am sickened by some of the promoters, at the moment I’m mostly in tune with Thomas Ptacek’s My AI Skeptic Friends Are All Nuts. It’s long and (fortunately) well-written and I (mostly) find it hard to disagree with.
it’s as simple as this: I keep hearing talented programmers whose integrity I trust tell me “Yeah, LLMs are helping me get shit done.” The probability that they’re all lying or being fooled seems very low.
Just to be clear, I note an absence of concern for cost and carbon in these conversations. Which is unacceptable. But let’s move on.
It’s worth noting that I learned two useful things from Ptacek’s essay that I hadn’t really understood. First, the “agentic” architecture of programming tools: You ask the agent to create code and it asks the LLM, which will sometimes hallucinate; the agent will observe that it doesn’t compile or makes all the unit tests fail, discards it, and re-prompts. If it takes the agent module 25 prompts to generate code that while imperfect is at least correct, who cares?
Second lesson, and to be fair this is just anecdata: It feels like the Go programming language is especially well-suited to LLM-driven automation. It’s small, has a large standard library, and a culture that has strong shared idioms for doing almost anything. Anyhow, we’ll find out if this early impression stands up to longer and wider industry experience.
Turning our attention back to cost, let’s assume that eventually all or most developers become somewhat LLM-assisted. Are there enough of them, and will they pay enough, to cover all that investment? Especially given that models that are both open-source and excellent are certain to proliferate? Seems dubious.
Suppose that, as Ptacek suggests, LLMs/agents allow us to automate the tedious low-intellectual-effort parts of our job. Should we be concerned about how junior developers learn to get past that “easy stuff” and on the way to senior skills? That seems a very good question, so…
Learning
Quite likely you’ve already seen Jason Koebler’s Teachers Are Not OK, a frankly horrifying survey of genAI’s impact on secondary and tertiary education. It is a tale of unrelieved grief and pain and wreckage. Since genAI isn’t going to go away and students aren’t going to stop being lazy, it seems like we’re going to re-invent the way people teach and learn.
The stories of students furiously deploying genAI to avoid the effort of actually, you know, learning, are sad. Even sadder are those of genAI-crazed administrators leaning on faculty to become more efficient and “businesslike” by using it.
I really don’t think there’s a coherent pro-genAI case to be made in the education context.
Professional communication
If you want to use LLMs to automate communication with your family or friends or lovers, there’s nothing I can say that will help you. So let’s restrict this to conversation and reporting around work and private projects and voluntarism and so on.
I’m pretty sure this is where the people who think they’re going to make big money with AI think it’s going to come from. If you’re interested in that thinking, here’s a sample; a slide deck by a Keith Riegert for the book-publishing business which, granted, is a bit stagnant and a whole lot overconcentrated these days. I suspect scrolling through it will produce a strong emotional reaction for quite a few readers here. It’s also useful in that it talks specifically about costs.
That is for corporate-branded output. What about personal or internal professional communication; by which I mean emails and sales reports and committee drafts and project pitches and so on? I’m pretty negative about this. If your email or pitch doc or whatever needs to be summarized, or if it has the colorless affectless error-prone polish of 2025’s LLMs, I would probably discard it unread. I already found the switch to turn off Gmail’s attempts to summarize my emails.
What’s the genAI world’s equivalent of “Tl;dr”? I’m thinking “TA;dr” (A for AI) or “Tg;dr” (g for genAI) or just “LLM:dr”.
And this vision of everyone using genAI to amplify their output and everyone else using it to summarize and filter their input feels simply perverse.
Here’s what I think is an important finding, ably summarized by Jeff Atwood:

Seriously, since LLMs by design emit streams that are optimized for plausibility and for harmony with the model’s training base, in an AI-centric world there’s a powerful incentive to say things that are implausible, that are out of tune, that are, bluntly, weird. So there’s one upside.
And let’s go back to cost. Are the prices in Riegert’s slide deck going to pay for trillions in capex? Another example: My family has a Google workplace account, and the price just went up from $6/user/month to $7. The announcement from Google emphasized that this was related to the added value provided by Gemini. Is $1/user/month gonna make this tech make business sense?
What I can and can’t buy
I can sorta buy the premise that there are genAI productivity boosts to be had in the code space and maybe some other specialized domains. I can’t buy for a second that genAI is anything but toxic for anything education-related. On the business-communications side, it’s damn well gonna be tried because billions of dollars and many management careers depend on it paying off. We’ll see but I’m skeptical.
On the money side? I don’t see how the math and the capex work. And all the time, I think about the carbon that’s poisoning the planet my children have to live on.
I think that the best we can hope for is the eventual financial meltdown leaving a few useful islands of things that are actually useful at prices that make sense.
And in a decade or so, I can see business-section stories about all the big data center shells that were never filled in, standing there empty, looking for another use. It’s gonna be tough, what can you do with buildings that have no windows?
Perfectly Different Colors 31 May 2025, 7:00 pm
This considers how two modern cameras handle a difficult color challenge, illustrated by photos of a perfect rose and a piano.
We moved into our former place in January 1997 and, that summer, discovered the property included this slender little rose that only had a couple blossoms every year, but they were perfection, beautifully shaped and in a unique shade of red I’d never seen anywhere else (and still haven’t). Having no idea of its species, we’ve always called it “our perfect rose”.
So when we moved last year, we took the rose with us. It seems to like the new joint, has a blossom out and two more on the way and it’s still May.
I was looking at it this morning and it occurred to me that its color might be an interesting challenge to the two fine cameras I use regularly, namely a Google Pixel 7 and a Fujifilm X-T5.
First the pictures.


Limitations
First of all, let’s agree that this comparison is horribly flawed. To start with, by the time the pixels have made it from the camera to your screen, they’ve been through Lightroom, possibly a social-media-software uploader and renderer, and then your browser (or mobile app) and screen contribute their opinions. Thus the colors are likely to vary a lot depending where you are and what you’re using.
Also, it’s hard to get really comparable shots out of the Pixel and Fuji; their lenses and processors and underlying architectures are really different. I was going to disclose the reported shutter speeds, aperture, and ISO values, but they are so totally non-comparable that I decided that’d be actively harmful. I’ll just say that I tried to let each do its best.
I post-processed both, but limited that to cropping; nothing about the color or exposure was touched.
And having said all that, I think the exercise retains interest.
Which?
The Pixel is above, the Fuji below.
The Pixel is wrong. The Fuji is… not bad. The blossom’s actual color, to my eye, has a little more orange than I see in the photo; but only a little. The Pixel subtracts the orange and introduces a suggestion of violet that the blossom, to my eye, entirely lacks.
Also, the Pixel is artificially sharpening up the petals; in reality, the contrast was low and the shading nuanced; just as presented by the X-T5.
Is the Pixel’s rendering a consequence of whatever its sensor is? Or of the copious amount of processing that contributes to Google’s widely-admired (by me too) “computational photography”? I certainly have no idea. And in fact, most of the pictures I share come from my Android because the best camera (this is always true) is the one you have with you. For example…

That same evening we took in a concert put on by the local Chopin Society featuring 89-year-old Mikhail Voskresensky, who plays really fast and loud in an old super-romantic style, just the thing for the music: Very decent Beethoven and Mozart, kind of aimless Grieg, and the highlight, a lovely take on Chopin’s Op. 58 Sonata, then a Nocturne in the encores.
Anyhow, I think the Camera I Had With Me did fine. This is Vancouver’s oldest still-standing building, Christ Church Cathedral, an exquisite space for the eyes and ears.
Maybe I’ll do a bit more conscious color-correction on the Pixel shots in future (although I didn’t on the piano). Doesn’t mean it’s not a great camera.
Comparing Numbers Badly 30 May 2025, 7:00 pm
This is just a gripe about two differently bad ways to compare numbers. They share a good alternative.
“Order of magnitude”
Typically sloppy usages: “AI increases productivity by an order of magnitude”, “Revenue from recorded music is orders of magnitude smaller than back in the Eighties”.
Everyone reading this probably already knows that “order of magnitude” has a precise meeting: Multiply or divide by ten. But clearly, the people who write news stories and marketing spiels either don’t, or are consciously using the idioms to lie. In particular, they are trying to say “more than” or “less than” in a dramatic and impressive-sounding way.
Consider that first example. It is saying that AI delivers a ten-times gain in productivity. If they’d actually said “ten times” people would be more inclined to ask “What units?” and “How did you measure?” This phrase makes me think that its author is probably lying.
The second example is even more pernicious. Since “orders” is plural, they are claiming at least two orders of magnitude, i.e. that revenue is down by at least a factor of a hundred. The difference between two, three, and four orders of magnitude is huge! I’d probably argue that the phrase “orders of magnitude” should probably never be used. In this case, I highly doubt that the speaker has any data, and that they’re just trying to say that the revenue is down really a lot.
The solution is simple: Say “by a factor of ten” or “ten times as high” or “at least 100 times less.” Assuming your claim is valid, it will be easily understood; Almost everyone has a decent intuitive understanding of what a ten-times or hundred-times difference feels like.
“Percent”
What actually got me started reading this was reading a claim that some business’s “revenue increased by 250%.” Let’s see. If the revenue were one million and it increased by 10%, it’d be 1.1 million. If it increased by 100% it’d be two million. 200% is three million. So what they meant by 250% is that the revenue increased by a factor of 3.5. It is so much easier to understand “3.5 times” than 250%. Furthermore, I bet a lot of people intuitively feel that 250% means “2.5 times”, which is just wrong.
I think quoting percentages is clear and useful for values less than 100. There is nothing wrong with talking about a 20% increase or 75% decrease.
So, same solution: For percentages past 100, don’t use them, just say “by a factor of X”. Once again, people have an instant (and usually correct) gut feel for what a 3.5-times increase feels like.
“But English is a living language!”
Not just living, but also squirmy and slutty, open to both one-night stands and permanent relationships with neologisms no matter how ugly and imports from other dialects no matter how sketchy. Which is to say, there’s nothing I can do to keep “orders of magnitude” from being used to mean “really a lot”.
In fact, it’s only a problem when you’re trying to communicate a numeric difference. But that’s an important application of human language.
Perversely, I guess you could argue that these bad idioms are useful in helping you detect statements that are probably either ignorant or just lies. Anyhow, now you know that when I hear them, I hear patterns that make me inclined to disbelieve. And I bet I’m not the only one.
CL XLVI: Happy Colors 27 May 2025, 7:00 pm
Last weekend we were at our cabin on Keats Island and I came away with two cottage-life pictures I wanted to write about. To write cheery stuff actually, a rare pleasure in these dark days. Both have a story but this first one’s simple.

It’s just an ordinary evergreen tree, not very tall, nothing special about it. But spring’s here! So at the end of each branch there’s a space where the needles are new and shout their youth in light green, a fragile color as compared to the soberly rich shade of the middle-aged needles further up the branch. Probably a metaphor for something complicated but I just see a tree getting on with the springtime business of tree-ness. Good on it.
Now a longer story. What happened was, we had an extra-low tide. Tide is a big deal, we get 17 vertical feet at the extremes which can cause problems for boats and docks and if you happen to arrive with several days worth of supplies at low tide well it sucks to be you, because you’re gonna be toting everything up that much further.
But I digress.

I went for a walk at low tide because you see things that are usually mostly hidden. For example these starfish, also known as sea stars or even “asteroids”. No, really, check that link.
These are Pisaster ochraceus, distinguished by that pleasing violet color. Have a close look. They’re intertidal creatures hiding from the unaccustomed light and air. The important thing is that they’re more or less whole, which is to say free of wasting disease, of which there’s been a major epizootic in recent years. The disease isn’t subtle, it makes their arms melt away into purple goo; extremely gross.
Plus, ecologies being what they are, there are downstream effects. Sea stars predate on sea urchins only recently they haven’t been because wasting disease. It turns out that sea urchins eat the kelp that baby shrimp trying to grow up hide in. Fewer stars, more urchins, less prawns. Which means that the commercial prawn-fishers have been coming up empty and going out of business.
Anyhow, seeing a cluster of disease-free stars is nice, whether you’re in the seafood business or you just like the stars for their own sake, as I do.
And light-green needles too. And spring. Enjoy it while you can.
The Lens of Spring 17 May 2025, 7:00 pm
Back in the early days of this blog, I used to publish posts that were mostly pictures of plants and flowers. Especially at this time of year. I think that energy went into Twitter and now the Fediverse, where it’s so easy to take a picture and post it right then. This week I got a freshly-repaired lens back from the shop and it put me in the mood to get closer to the botanical frenzy springing at us from every direction. Herewith four pix of two plants, one of a lens, and more thoughts on a familiar subject: Whether it’s better to repair than to replace.
The lens, by the way, was the Fuji 18-55 oops its full name is “Fujinon XF18-55mmF2.8-4 R LM OIS” so there. I bought it in March of 2013 and have dropped it more than once; I have retained 1,432 pictures taken with it over the years. But then it stopped working.
More words on that later, but pictures first.

Roses have names and this one is “Fru Dagmar Hastrup”. Therein lies a tale that is either 17 or 111 years old, depending how you count.
That’s the first picture I took with the repaired 18-55. But then I thought that the whole point of this basic zoom was that you could go wide to capture big things, or long to, well, zoom in on ’em. So I went out front.

Trees have names too. This is a White Ash (Fraxinus americana).
That ash is one of the trees lining the street we moved onto last October. It’s really immense. Let’s crank the zoom way wide and capture most of it. Doing this reveals really great geometry, so let’s subtract the color and add some Silver Efex sizzle.

And then we can zoom back in.

The closer you get, the better it looks.
Fixing that lens
I like quirky fast compact opinionated prime lenses just as much as the next photoenthusiast, but a decent midrange zoom is just too useful not to have. I could’ve replaced this one with the new-fangled 16-50mm (also has a long complicated Real Name but never mind). That would cost me extra money and might not even be better.
So I poked around on the Fujifilm Web site and sure enough, they offer repair as a service, just package it up and mail it in. A few days after doing so I got an email quoting me a price and asking for approval, which I granted. You shouldn’t be surprised. Way back in 2011 I wrote Worth Fixing, the exemplar of which was a different excellent lens. And then just last year my Parable of the Sofa touched a few nerves. So I didn’t think very hard about it.
But then I realized I hadn’t even checked whether the price was reasonable. So I turned to eBay and, well, I could have got a mint-condition secondhand 18-55 for less than the cost of the repair. Not a lot less, but still. Oh well. If it were reasonable to care about a single instance of a standardized commercial product, I’d care about that lens.
Anyhow, it works pretty well. Showing its age, but still reasonably handsome.

If I live long enough maybe I’ll take another thousand pictures with it.
Long Links 6 May 2025, 7:00 pm
Another Long Links curation (the 31st!); substantial pieces of reading (or watching or listening) that you probably don’t have time to take in all of. One or two, though, might reward your attention. The usual assortmet of music, geekery, and cosmology.
Galactic clusters
Ever heard of Laniakea? Neither had I. It’s another word for our home. This 7-minute YouTube video, The Laniakea supercluster of galaxies, is graceful and mind-expanding; highly recommended.
Atom Heart Mother
I was sitting up late, pretty mellow, and Google Music showed me Atom Heart Mother as performed by Japanese tribute band Pink Floyd Trips in 2016. It woke me right up. The Japanese hipsters are instrumentally strong and use keyboards for the acoustic-instrument parts. As for the vocals, well, oh my oh my, definitely next level. Good stuff.
Which made me curious about other performances of Atom Heart Mother. Turns out Floyd recorded a 1971 performance, coincidentally also from Japan. Obviously they’re competent, but they’re just four guys and the keyboard technology was way more primitive back then, so they’re at a disadvantage compared to the resources they had in the studio when recording it, or the technology deployed by PF Trips. A lot of the visuals are of the band arriving in and traveling around Japan, which is OK, because their performances in that era weren’t particularly visually stimulating. Credit to Gilmour for hitting the high notes (albeit with some electronic assist), but once again, he’s at a disadvantage compared to the awesome Japanese singers.
The arrangement is quite a bit different than the original on the eponymous album and, within the limitations, is good.
There’s a cover by “Pussycherry et l'Orchestre d'harmonie de Clermont Ferrand” which I abandoned partway through because the orchestra just isn’t very good, clumsy and harsh. There is a nice little cello part though.
I will link to Orchestre Philharmonique de Radio France with Ron Geesin at the Théâtre du Chatelet, once again an orchestra and a chorus. Ron Geesin is the guy that Floyd hired to do all the orchestral stuff after they’d recorded the basic tracks and went on tour. The orchestra is way better but disappointingly equals neither Geesin’s original take on the album, nor PF Trips. And the big choir doesn’t come close to those two Japanese women.
There are more performances out there, but I had to go to bed.
C2PA C2PA C2PA
I have written quite a bit about C2PA and other “Content Authenticity” initiative stuff. Recently, Adobe has released more C2PA-enabling technology in several of its apps, and there is commentary from DPReview and PetaPixel.
If you care about this stuff like I do you’ll probably enjoy reading both pieces. But they (mostly) miss what I think is the key
point. The biggest value offered by this stuff is establishing provenance, and the most important place to establish provenance
is on social media. Knowing that a pic on Fedi or Bluesky was first uploaded by @joe@somewhere.example is highly
useful in helping people decide whether it’s real or not, and would not require a major technical leap from any social-media
provider.
Less attention
Joan Westerberg’s excellent Notes from the Exit: Why I Left the Attention Economy is full of passion and truth. About stepping off the “content creator” treadmill, she writes:
Leaving the attention economy doesn’t mean vanishing. It means choosing to matter to fewer people, more deeply. It means owning the means of distribution. It means publishing like a human being instead of a content mill. It means you stop playing to the house odds and start building your own game.
And the rest is just as good. For what it’s worth, what she’s describing is what I’ve been trying to do in this space for the last 22 years.
Defective outlook
I don’t read The Register often enough; for many years they’ve been full of fresh takes and exhibited a usefully belligerant attitude. For example, When even Microsoft can’t understand its own Outlook, big tech is stuck in a swamp of its own making excoriates “the weird cruft that happens when Microsoft saws bits of our limbs off to make us fit into whatever profit center is running strategy today.” I actually disagree with some of the article, as I often do with the Reg, but I enjoyed reading it anyhow.
A billion times a second
Time to put on your hardcore-geek hat and look at Formally verified cloud-scale authorization. A group at AWS replaced a single heavily-used API call implementation with formally-verified code, simultaneously making it smaller and faster. The link is to an overview piece, the full PDF is here.
These are not lightweight technologies and this was not a cheap project; a lot of people did a lot of work and these are not junior people. But when what you’re working on is this call:
Answer evaluate(List<Policy> ps, Request r)
That call is at the core of where AWS grants or denies access by anything to anything, and it’s called more than a billion times a second. That’s billion with a B. A situation where this kind of investment isn’t merely justifiable, it’s a no-brainer. I know a couple of the people on the authors list, and I offer all of them my congratulations. Strong work!
Decarbonization at sea
Regular readers know that my family has a boat, that we’re trying to decarbonize our lives, and that the boat has been the hardest part of that.
So, I pay close attention to the latest news from the electric-boat scene. I’m starting to gain confidence that in a single-digit number of years we’ll be using a quieter, cheaper, more environmentally praiseworthy vessel of some sort. So, in case anybody has similar worries, here are snapshots from a few of the more viable electric-boat startups: Navier, Torqueedo, X Shore, Candela. Also, here’s Aqua superPower, which wants to bring dockside charging to the electric-boat scene. And finally, here is the Electric boats category from the always-useful electrek electric-mobility site.
Southsiders 4 May 2025, 7:00 pm
Ever been to a soccer match and noticed the “supporters section”, full of waving flags and drummers and wild enthusiasm? Last Saturday I went there. And marched in their parade, even. I could claim it was anthropology research. But maybe it’s just old guys wanna have fun. Which I did. Not sure if I will again.
For the rest of this piece, when I say “football” I mean fútbol as in soccer, because that‘s what everyone on the scene says.
Background
MLS (for Major League Soccer) is the top-level football league in North America and, depending on whose ratings you believe, the 9th or 10th strongest league in the world. At the moment, the Vancouver Whitecaps are the strongest team in MLS and are ranked #2 in Concacaf which means North and Central America. That may become #1 if they win the win the Champions Cup Final on June 1st in Mexico City, against #1-ranked Cruz Azul.
Who knows if these good times will last, but for the moment it means they’re kind of a big deal here my home town. I’ve become a fan, because the Whitecaps are fun to watch.
Mind you, the team is for sale and will probably be snapped up by a Yankee billionaire and relocated to Topeka or somewhere.
When I’ve been to Whitecaps games, I’ve always been entertained by the raucous energy coming out of the supporters section. They provide a background roar, shout co-ordinated insults at the other team and referee, have a drum section, and feature a waving forest of flags.
Southsiders
They’re called that because they inhabit the south end of the stadium, behind the goal that the Whitecaps attack in the second half. Check out the Web site.
So, on a manic impulse, I joined up. It didn’t cost much and got me a big-ass scarf with “Vancouver” on one side and “Southsiders” on the other. Which I picked up, along with a shiny new membership card, at Dublin Calling, a perfectly decent sports bar where the membership card gets you a discount. I have to say that the Southsiders people were friendly, efficient, and welcoming.
My son was happy to come along; we got to the bar long enough before The Parade to have a beer and perfectly OK bar food at what, especially with the discount, seemed a fair price. This matters because the food and beer at the stadium is exorbitantly priced slop.
Alternatives
Since I wrote this, I learned that there are actually four different fan clubs. Especially, check out Vancouver Sisters.
The Parade
Forty-five minutes before game time, the fans leave Dublin Calling a couple hundred strong and march to the stadium, chanting dopey chants and singing dopey songs and generally having good clean fun. It’s a family affair.

Note: Kid on Dad’s shoulders. Flags. Spectators, and here’s a thing: When you’re in a loud cheerful parade, everybody smiles at you. Well, except for the drivers stuck at an intersection. Since we’re Canadian we’re polite, so we stop the parade at red lights. Sometimes, anyhow.

Note: Maximal fan. Scarves held aloft (this happens a lot). Blue smoke. Flags in Whitecaps blue and Canada red.
When the parade gets to the stadium, everyone kneels.


After a bit, someone starts a slow quiet chant, then they wind it up and up until everyone explodes to their feet and leaps around madly. That’s all then, time to pile into the stadium.

Which is visually impressive on with the lid open on a sunny day.
Indoor fun
The Southsiders section is General Admission, pick anywhere to stand. And I mean stand, there’s no sitting down while the game’s on. There’s a big flag propped up every half-dozen seats or so you can grab and wave when the spirit moves you. There’s a guy on a podium down at the front, facing the crowd, and he co-ordinates the cheers and songs and… He. Never. Stops.
The Southsiders gleefully howl in joy at every good Whitecaps move and with rage at every adverse whistle, have stylized moves like for example whenever the opposing keeper launches a big goal kick everyone yells “You fat bastard!” No, I don’t know why.
When I shared that I was going to do this crazy thing people wondered if it was safe, would I get vomited on, was there violence, and so on. In the event it was perfectly civilized as long as you don’t mind a lot of noise and shouting. The beer-drinking was steady but I didn’t see anyone who seemed the worse for the wear. If it weren’t for all the colorful obscenity I’d be comfy bringing a kid along.
The crowd is a little whiter than usual for Vancouver, mostly pretty young, male dominated, with a visible gay faction. Nothing special.

Note: Canadian and rainbow flags. Somewhat obstructed view; the flags are out because a goal has just been scored, you can see the smoke from the fireworks. The opposing goal is a long way away.
What’s good: Being right on top of any goals scored at the near end. The surges of shared emotion concerning the action in the game.
What’s bad: Standing all through the game. The action at the other end is too far away. The songs and chants grow wearing after a while.
The game
The Whitecaps won, which was nice. It was pretty close, actually, against a team that shouldn’t be much of a threat. But then, most of Vancouver’s best players were out in healing-from-injury or resting-from-overwork mode. I still think the Whitecaps are substandard at working the ball through the middle of the field, but do well at both ends; At the moment the stats seem to say that they’re on top both at scoring and preventing goals.
Here’s what to do if you’re watching a game: If either Pedro Vite (#45) or Jayden Nelson (#7) get the ball, lean in and focus. Both those guys are lightning in a bottle. I’ve enjoyed watching this team more than any other Vancouver sports franchise ever. It probably can’t last.
Will I do the Southsiders section again? Maybe. I suspect I’ll enjoy their energy and edge just as much even when I’m not in the section, plus I’ll get to sit down. We’ll see.
My son and I had fun. No regrets.
Censoring Social Media 28 Apr 2025, 7:00 pm
In mid-April we learned about Bluesky censoring accounts as demanded by the government of Türkiye. While I haven’t seen coverage of who the account-holders were and what they said, the action followed on protests against Turkish autocrat Erdoğan for ordering the arrest of an opposition leader — typical behavior by a thin-skinned Führer-wannabe. This essay concerns how we might think about censorship, its mechanics, and how the ecosystems built around ActivityPub and ATproto can implement and/or fight it.
That link above is to TechCrunch’s write-up of the situation, which is good. There’s going to be overlap between that and this but neither piece is a subset of the other, so you might want to read TechCrunch too.
Censorship goals and non-goals
How, as the community of people who live and converse online, should we want our decentralized social media to behave?
I’m restricting this to decentralized social media because the issues around censorship differ radically between a service owned and controlled by a profit-seeking corporation, and an ecosystem of interoperating providers who may not be in it for the money.
So, from the decentralized point of view, what should be the core censorship goals? As Mencken said, “For every complex problem there is an answer that is clear, simple, and wrong.” Here are two of those:
No censorship. Let people say what they will and the contest of ideas proceed. Freedom of speech must be absolute.
Suppress any material which is illegal in the jurisdiction where the human participant is located. Stop there, because making policy in this area is not the domain of of social-media providers.
“Free speech”?
The absolutists’ position is at least internally consistent. But it has two fatal flaws, one generic and one specific. In general, a certain proportion of people are garbage and will post terrible, hateful, damaging things that make the online experience somewhere in the range between unpleasant and intolerable, to the extent that many who deserve to be heard will be driven away.
And specifically, history teaches us that certain narratives are dangerous to civic sanity and human life: Naziism, revanchism, hypernationalism, fomenting ethnic hatred, and so on.
Another way to put this: Everyone has a basic right to free speech, but nobody has a right to be listened to.
So, the Free Speech purists can now please show themselves out. (Disclosure: I didn’t mean that “please”.)
“Rule of law”?
I can get partially behind this. If you’re running a social-media service in a civilized democratic country and posting X is against the law, you’d better think carefully about allowing X. (Not saying that civil disobedience is always wrong, just that you need to think about it.)
But mostly no. The legalist approach suffers from positive and negative failures. Negative, as in censoring-is-wrong: I really DGAF about Turkish legal restrictions, because they’re more or less whatever Erdoğan says they are, and Erdoğan is a tinpot tyrant. Similarly, on Trump’s current trajectory it’ll soon be illegal to express anti-Netanyahu sentiment in the USA.
Positive, as in not-censoring is wrong: Lolicon is legal in Japan and treated like CSAM elsewhere. Elsewhere is right, Japan is wrong. Another example: Anti-trans hate is increasingly cheerled by conservative culture warriors all over the place and is now the official policy of the British government. Sir Keir Starmer would probably be suspended from my Mastodon instance and invited to find somewhere else, except for somewhere else would be mass-defederated if it tolerated foolish bigots like Starmer.
How Bluesky does it
(I should maybe say “How ATproto does it” but this seems more reader-friendly.) It’s not as though they pushed some button and silenced the hated-by-Erdoğan accounts. In fact, it’s subtle and complicated. For details, see Bluesky, censorship and country-based moderation by Laurens Hof at The Fediverse Report. Seriously, if you think you might have an opinion about Bluesky and what they’re doing, go read Hof before you share it.
Having said that, I think I can usefully offer a short form. Bluesky supports the use of multiple composable moderation services, and client software can decide which of them to subscribe to. It provides a central moderation service aimed at stopping things like CSAM and genocide-cheerleading that’s designed to operate at the scale of the whole network, which seems good to me.
It also offers “geographic moderation labelers”, which can attach “forbidden” signals to posts which are being read by people in particular areas. That’s what they did in this case; the Erdoğan-hated accounts had those labels attached to their posts, but only for people who are in Türkiye.
The default Bluesky client software subscribes to the geographic labeler and does as it’s told, which made Erdoğan and his toadies happy.
But anyone can write Bluesky client software, and there’s nothing in the technology that requires clients to subscribe to or follow the instructions of any moderation service. One alternate client, Deer.social, is a straightforward fork of the default, but with the geographic moderation removed. (It may have other features but looks about like basic Bluesky to me.)
How the Fediverse does it
(I should maybe say “How ActivityPub does it” or “How Mastodon does it” but…) Each instance does its own moderation and (this is important) makes its own decision as to which other instances to federate with. There are plenty of sites out there running Fediverse software that are full of CSAM and Lolicon and Nazis and so on. But the “mainstream” instances have universally defederated them, so it’s rare to run across that stuff. I never do.
To make things easy, there are “shared block-lists” that try to keep up-to-date on the malignant instances. It’s early days yet but I think this will be a growth area.
Most moderation is based on “reporting” — if you see something you think is abusive or breaks the rules, you can hit the “report” button, and the moderators for your instance and the source instance will get messaged and can decide what to do about it.
The effect is that there is a shared culture across a few thousand “mainstream” instances that leads, in my opinion, to a pretty pleasing atmosphere and low abuse level. We have a problem in that it’s still too easy to for a bad person to post abusive stuff in a way that is hard for moderators to see, but it’s being worked on and I’m optimistic.
Dealing with Erdoğan: Bluesky
So, suppose we want our social-media services to route around Erdoğan’s attempts to silence his political opponents. I do. How effective would Bluesky and the Fediverse be at that?
Bluesky makes it easy: Just use an alternate client. Yay! Except for, most people don’t and won’t and shouldn’t have to. Boo!
Still I dunno, in a place where the politics is hot, the word might get out on the grapevine and a lot of people could give another client a try. Maybe? Back in the day a lot of people used alternate Twitter clients, until Twitter stomped those out. I’m not smart enough to predict whether this could really be effective at routing round Erdoğan. I lean pessimistic though.
Wait, what about the Bluesky Web interface? Who needs a client anyhow! No luck; it turns out that that’s a big fat React app with mostly the same code that’s in the mobile apps. Oh well.
Anyhow, this ignores the real problem. Which is that if Erdoğan’s goons notice that people are dodging the censorship they’ll go nuclear on Bluesky (the company) and tell them to just stop displaying those people’s posts and to do it right fucking now.
If that doesn’t work, they have a lot of options, starting with just blocking access to bsky.app, and extending to arresting any in-country staff or, even better, their families. And throwing them in an unheated basement. I dunno, a courageous and smart company might be able to fight back, but it wouldn’t be a good situation.
And that’s a problem, because even though the ATproto is by design decentralized, in practice there’s only one central service that routes the firehose of posts globally. So my bet would be that Erdoğan wins.
Dealing with Erdoğan: Fediverse
This is a very different picture. Block access to the app and a lot of people won’t notice because they use the browser, connecting to one of the thousands of Fediverse instances, desktop or mobile, and it’ll work fine. OK, how about finding out which instances the people they’re trying to ban are on, and going after those instances? If the instance is in a rule-of-law democracy, the Turks would probably be told to go pound sand.
OK, so what if the Turks ferociously attacked the home servers of the Thought Criminals? No problemo, they’d migrate to a more resilient instance and, since this is the Fediverse, their followers might never notice, they’d just come along with them.
Pretty quickly the Erdoğan gang are gonna end up playing whack-a-mole. In fact I think it’s going to be really, really hard in general for oppressive governments to censor the Fediverse. Not impossible; the people who operate the Great Firewall would probably find a way.
When Bluesky progresses to the point that there isn’t a single essential company at the center of everything, it should be censorship-resilient too, for the same reasons.
Take-aways
I think that, to resist misguided censorship by misguided governments, we need (at least) these things:
A service with no central choke-points, but rather a large number of independent co-operating nodes.
Accounts, and the follower relationships between them, are not tied to any single node.
Clearly these conditions are necessary; we don’t know yet whether or not they’re sufficient. But I’m generally optimistic that decentralized social media has the potential to offer a pretty decent level of censorship resistance.
CL XLV: Island Spring 21 Apr 2025, 7:00 pm
Join me for a walk through a rain forest on a corner of a small island. This is to remind everyone that even in a world full of bad news, the trees are still there. From the slopes leading down to the sea they reach up for sunshine and rain, offering no objections to humans walking in the tall quiet spaces between them.
[The island is Keats Island, where we’ve had a cabin since 2008. It’s mostly just trees and cabins, you can buy an oceanfront mansion for millions or a basic Place That Needs Work for much less (as we did) or you can camp cheap. Come on over sometime.]
On the path up from the water to the cabin there’s this camellia that was unhappy at our home in the city, its flowers always stained brown even as they opened. So we brought it to the island and now look at it!

One interior shot. On this recent visit I wired up this desk, a recent hand-me-down from old friend Tamara.

When I got it all wired up I texted her “Now I write my masterpiece” but instead I wrote that one about URI schemes, no masterpiece but I was happy with it. And anyhow, it’s lovely space to sit and tap a keyboard.
Now the forest walk.

These are rain forests and they are happy in their own way when it rains but I’m a Homo sapiens, we evolved in a sunny part of the world and my eyes welcome all those photons.
In 2008 I was told that the island had been logged “100 years ago”. So most of these are probably in the Young-Adult tree demographic, but there are a few of the real old giants still to be seen.
Sometimes the trees seem to dance with each other.


Both of those pictures feature (but not exclusively) Acer macrophyllum, the bigleaf Maple, the only deciduous tree I know of that can compete for sun with the towering Cedar/Fir/Hemlock evergreens. It’s beautiful both naked (as here) and in its verdant midsummer raiment.
But sometimes when you dance too hard you can fall over. He are two different photographic takes on a bigleaf that seems to have lost its grip and is leaning on a nearby hemlock.


And sometimes you can just totally lose it.

It is very common in these forests to see a tree growing out of a fallen log; these are called “nurse logs”. It turns out to be a high-risk arboreal lifestyle, as we see here. It must have been helluva drama when the nurse rolled.
I’m about done and will end as I began, with a flower.

This is the blossom of a salmonberry (Rubus spectabilis) a member of the rose family. It has berries in late summer but they’re only marginally edible.
It’s one of the first blossoms you see in the forest depths as spring struggles free of the shackles of the northwest winter.
Go hug a tree sometime soon, it really does help.
Decentralizing Schemes 16 Apr 2025, 7:00 pm
I’m a fan of decentralized social media and that’s partly because I enjoy using it. But mostly because history teaches that decentralization is the best basis for sustainable, resilient online conversation. (Evidence? Email!) For the purpose of this essay, let’s assume that you agree with me. Let’s also assume that our online life is still Web-flavored. I’m going to describe a few unfortunate things that can happen in a decentralized world, then look at a basic built-in feature of the Web that might make the problems go away.
Let’s start with bad-experience scenarios
Sharing pain
Suppose I post a picture to my social-media feed and since Ash follows me, it shows up in their stream. They can favorite or boost it, but let’s suppose they think their friend Layla might like it too, so they grab the link and drop into their chat window with Layla, or maybe they send her an email.
By “link” I mean “URL”, and by “URL” I mean “URI” (the distinction will matter in a bit). Here’s what that looks like, first
on the Fediverse:
https://cosocial.ca/@timbray/114361121438267145
And on Bluesky:
https://bsky.app/profile/tbray.org/post/3lmxrkmwz5k2u
Layla sees the link and clicks it or taps it and yay, there’s the picture. She dislikes it and wants to add a negative comment. On the Fediverse, if it turns out she’s logged onto CoSocial.ca like me she’ll have no trouble, she can fire away. If she’s logged into another instance (and the Fediverse has thousands) she’s out of luck, even though she’s got a live Fediverse session. She can paste the URL or just “@timbray” into her search window and that might get her there indirectly if she’s lucky.
This is a bad experience.
On Bluesky, it’ll probably just work. Well, for now. Because while Bluesky is based on the
AT Protocol (ATproto for short) which is in theory decentralized, at the
moment Ash is logged into the “App View” at bsky.app just like I am, because in practice everybody
on Bluesky is.
But in a future where there are multiple ATproto App Views, which is to say when Bluesky becomes as decentralized as the Fediverse is today, we’re back with the Fediverse problem, because her browser doesn’t know that the URI identifies an ATproto post that she should be able to boost or like.
Client pain
There’s another problem in this scenario. Suppose Layla was logged into CoSocial.ca, but she wasn’t using the default Mastodon client, but rather an alternative such as Phanpy or Elk.zone. When Layla clicks on that link she won’t be in her fave Fedi client but back in vanilla Mastodon.
Not a good experience.
Post portability pain
Let’s look at the URI for a different Fediverse post of a pretty picture:
https://mastodon.cloud/@timbray/109508984818551909
It’s one of my posts all right, but it’s not from cosocial.ca, it’s from
mastodon.cloud, which was my first home on the Fediverse. I left it in December 2022 because it
was sold to another company which is sketchy, by which I mean
Lolicon-friendly.
Whatever I think of whoever’s running mastodon.cloud, I have a lot of posts over there, some of which I care
about. For now, they’re still there, but I’m not contributing any money to those guys, nor will I, so if they pull the plug and
vanish I can’t complain. Only if they do, so do all those posts that I cared about back then and still do a bit.
Another bad experience.
URIs and schemes
[Anyone who already understands URIs schemes and so on can skip to the next section.]
Let’s look at that Fediverse link again:
https://cosocial.ca/@timbray/114280972142347258
I call it a “URI” because that’s the official name for what it is. What they look like and how to use them are very thoroughly specified in several Internet Engineering Task Force publications starting with RFC3986. URLs are also URIs, but URIs can do surprising things that you’ve probably never seen in the world of ordinary URLs.
The crucial thing about both the Fediverse and Bluesky URIs is that they begin with the magic letters “https” followed by a
colon. All URIs
begin with a short string and a colon; the string is called the URI scheme. For each possible scheme, there’s a set of rules
saying how to handle URIs of that flavor. If it’s “https”, then the rules say, using that Fediverse URI as an example, to make
an encrypted connection to the server at cosocial.ca and ask it to send you
/@timbray/114280972142347258. You’ll get some bytes that represent what the URI identifies.
[Yes, I’m oversimplifying. Sorry.]
While most of the URLs you’re ever likely to encounter begin with “https:” there are other schemes. Suppose your email is
“tim@example.com”. Paste mailto:tim@example.com into your browser, hit Enter, and see what happens. This is a URI
whose scheme is “mailto” and it works just fine.
When I tried this just now on my Mac, all three of Safari, Firefox, and Chrome noticed that I use the Mimestream mail app and popped that up. Which shows that somewhere in this computer there’s a notion of a registered handler for a particular URI scheme. Which is exactly what URI schemes were designed for.
I mean, if I can install an email app to handle mailto: URIs, why can’t I install a Fediverse app to handle
fedi:?
There are lots of URI schemes! Here’s the official registry. Now, most of these are marked as “provisional” which means “we’re just reserving this scheme because we think we’re going to use it” and even among the ones that aren’t provisional, very few of them are in widespread enough use that you can expect your browser to handle them.
You’ll notice that the at: scheme is in there, registered by the Bluesky people (after I suggested they do so). For the
Fediverse, I see
web+ap: (which I’d never heard of before starting to
write this).
Let’s suppose that there were URI schemes for both ATproto (at:) and the Fediverse(I
suggest fedi:
rather than web+ap: for reasons I’ll discuss later).
Let’s also suppose that they were well supported by operating systems and browsers. I claim that this would help solve all three
of those pain
scenarios.
Solving sharing and client pain
Remember, Ash copied the URI for a post and dropped into their chat window with Layla; when Layla clicked it, she saw the post but couldn’t boost it or reply to it.
But suppose it began with either at: or
fedi: — then the computer or mobile would dispatch to whatever Layla uses to interact
with ATproto/Fediverse software, and it’d know how to go about opening that post in the way Layla expects so she can reply and
boost and so on. I’m ignoring
the details of how that’d work, and some of them are tricky, but this could be done.
Solving migration pain
This is a little more ambitious, but remember that “mastodon.cloud” post that might go away some day if the server does?
Suppose we change it slightly, like so:
fedi://mastodon.cloud/@timbray/109508984818551909
Once again, because it begins with “fedi:” not “https:”, the job would be handed off to Fediverse-savvy software. And since the Fediverse already knows how to migrate accounts from one server to another and bring your followers along, why shouldn’t it also copy your posts and store them somewhere, and when it hits that URI, remember “Oh wait, that @timbray@mastodon.cloud handle migrated a couple of times but that’s OK, I still have the posts from the old servers stored away so I can fetch that post rather than just giving up because mastodon.cloud went away”.
Now, as far as I know, Mastodon doesn’t have any capabilities like that, nor does any other Fediverse software. But once again, it’s a thing that could be done. And if we have a new URI scheme, there’d be a hook to hang that kind of software on.
At the moment, ATproto/Bluesky is a lot closer to being able to do this. Your ATproto account isn’t tied to the server you happen to be logged into when you posted it, it’s a long-lived asymmetric-crypto based thing and it assumes that there’ll be per-account storage not tied to any particular App View. Also posts are identified by content hash, which should be helpful.
But as far as I know, even with ATproto, if my browser’s visiting the bsky.app App View and I shoot a URL beginning
with https://bsky.app to someone on the blacksky.web.xyz App View, I don’t see how the browser can
figure out that that URL should invoke ATproto software.
But if it began at://bsky.capp, it’d be perfectly tractable (I think).
Scheme details and problems
There multiple proposals for a Fediverse URI scheme. I already mentioned web+ap: and then there’s
web+activitypub: from
silverpill (which may be the same?), and
fedi: from me. The “web+” ones are more descriptive but mine is
cooler and I think that matters.
The proposals include useful discussions of the issues, which include those discussed in this essay; if you care about this
stuff I think both would reward a read.
I also have to note this from Mastodon author Eugen Rochko back in 2022: “We've done this before but removed because browser support / UX was inadequate.”
(Before I go on I should point out that Eugen is right about support for alternate schemas in Web browsers being weak, but not all of them. On Android, any app can register itself to handle URIs of a particular scheme. I assume iOS has something similar? So this isn’t completely science-fictional.)
So using URI schemees isn’t a new idea and yeah, patchy browser support is a problem. The people who build Safari and Chrome and Firefox are busy and are fanatically concerned with security and stability for their billions of users, and if I go and tap them on the shoulder and say “Here are new schemes and here’s the decentralized-social-media software I want registered to handle them” they’re not gonna to just say “Okay” and do it.
Bit I dunno, the times they are a changin’. As Bluesky and the Fediverse build momentum, and the decentralized path forward looks more and more attractive, the case for new URI schemes probably becomes easier to make.
As it should. Because the notion of the URI is a core foundational piece of the Web’s architecture, and the design of URIs has multiple protocol support baked in, and the URI schemes exist specifically to enable it.
So, we should work on using it.
Coachella 2025 14 Apr 2025, 7:00 pm
Last weekend I spent a few hours watching Coachella on YouTube. The audio and video quality are high. It’s free of ad clutter, but maybe that’s because I pay for Google Music? The quality of the music is all over the map. If I read the schedule correctly, they’ll repeat the exercise next weekend, so I thought a few recommendations might be helpful. Even if it’s not available live, quite a few captures still seem to be there on YouTube, so check ’em out.
I tried sorting these into themes but that tied me in knots, so you get alphabetical order.

Lady Gaga brings it.
Blonde Redhead
Not sure what kind of music to call this, but the drums and guitar (played by identical twins Simone and Amedeo Pace) are both hot, and Kazu Makino on everything else has loads of charisma, and they all sang well. Didn’t regret a minute of my time with this one.
Ben Böhmer
I have no patience whatsoever for EDM. Deadmau5 and Zedd and their whole tribe should go practice goat-herding in Bolivia or anything else that’ll keep them away from audiences who want to hear music played by musicians. But there were multiple artists this year you could describe as X+EDM for some value of X, and much to my surprise a few of them worked.
(One that notably didn’t was Parcels, whose genius idea is EDM+Lightweight Aussie pretty-boy pop. On top of which, every second of their performance featured brilliant lights strobing away, shredding my retinas and forebrain. I say it’s EDM and I say to hell with it. Go back to Australia and stay.)
But Mr Böhmer not only held my attention but had my toes tappin’. His stuff isn’t just hot dance moves against recorded tracks, it’s moody and cool and phase-shifty and dreamy. It helps that he plays actual musical notes on actual keyboards.
Beth Gibbons
I thought “I remember that name.” (Sadly, on first glance at the schedule I did not in fact recognize many names.) Ms Gibbons was the singer for Portishead, standard-bearers of Trip-hop back in the day. Her voice sounds exactly the same today as it did three decades ago, which is to say vulnerable and lovely.
The songs were all new (aside from Portishead’s Glory Box) and good. Beth never had any stage presence and still doesn’t, draped motionless over the mike except when she turns away from the crowd to watch someone soloing.
What made the show a Coachella highlight was the band, who apparently had just arrived from another planet. It was wonderfully strange as in I didn’t even know what some of the instruments were. Anyhow it all sounded great albeit weird, the perfect complement to Beth’s spaced-out (I mean that in the nicest way) vocal arcs.
Go-Gos
This posse of sixtysomething women won my heart in the first three seconds of their set with a blast of girl-group punk/surf guitar noise and a thunderous backbeat. The purest rock-&-roll imaginable, played with love and bursting with joy. They can sing, they can play, they still have plenty of moves. It‘s only rock and roll but I like it, like it, yes I do.
HiTech
OK, this is another X+EDM, where the X is “Ghettotech, house, Rap & Miami base” (quoting their Web site). I have no idea what “Miami base” is but I guess I like it, because they’re pretty great. Outta Detroit.
Their set was affably chaotic, the rapping part sharp-edged and hot, and they had this camera cleverly mounted on the DJ deck giving an intense close-up of whichever HiTech-ers were currently pulling the levers and twisting the knobs. Sometimes it was all three of them and that was great fun to watch.
I’m an elderly well-off white guy and am not gonna pretend to much understanding of any of HiTech’s genres, but I’m pretty confident that a lot of people would be entertained.
Kraftwerk sigh
They are historically important but the show, I dunno, I seem to recall being impressed in 1975 but it felt kinda static and tedious. The only reason I mention them is that a few of their big video-backdrop screens, near the start of the set, were totally Macrodata Refinement, from Severance. I wonder if any of the showrunners were Kraftwerk fans?
LA Phil, conducted by Gustavo Dudamel
Give Coachella credit for giving this a try. Dudamel is a smart guy and put together a program that wasn’t designed to please a heavy classics consumer like me. I mean, opening with Ride of the Valkyries? But there were two pieces of Bach and the orchestra turned into a backup band for Laufey, an Icelandic folk/jazz singer, a Gospel singer/choir, and some other extremely random stuff. If you’re not already a classics fan, this might open your eyes a bit.
Lady Gaga
I’m sure you’ve already read one or two rave write-ups about this masterpiece. It’s going to be one of the performances remembered by name forever, like Prince at the Superbowl or Muddy Waters at the Last Waltz. They built a freaking opera house in the desert, and that makes me wonder what the Coachella economics are; someone has to pay for this stuff, do Gaga and Coachella split it or is it the price of getting her to come and play?
To be fair, as the review in Variety accurately noted, it was pretty well New-York-flavored hoofing and belting wrapped in a completely incomprehensible Goth/horror narrative. So what?! The songs were great. The singing was fantastic and the dancing white-hot, plus she had a pretty hard-ass live metal-adjacent band and an operatic string section, and she brought her soul along with her and unwrapped it. It was easy to believe she loved the audience just as much as she said. She didn’t leave anything on the stage. They should make it into a big-screen movie.
I did feel a little sorry for the physical audience, quite a bit of the performance seemed to be optimized for couch potatoes with big screens like for example me. Anyhow, if you get a chance to see this one don’t miss it.
Other headliners?
There were three nights and thus three headliners. You’ll notice that I only talked up Friday night’s Lady-Gaga set. That’s because the other two were some combination of talentless and uninspired and offensive. Obviously I’m in a minority here, they wouldn’t get the big slots if millions didn’t love ’em. And I like an unusually wide variety of musical forms. But not that shit.
The CoSocialist Future 5 Apr 2025, 7:00 pm
This week marks the second anniversary of the launch of the CoSocial.ca Mastodon server, which is one leg of my online presence (the other is this blog.) I’ve never been more convinced that online social interaction has to change paths and take a new direction. And I think CoSocial has lessons to teach about that direction. Here are some.
A personal note: I’ve been fortunate in that bits and pieces of my career have felt like building the future. For example, right now, about the Fediverse generally and CoSocial in particular. In this essay I’ll try to explain why. But it’s a fine feeling.
Decentralized
This is maybe the biggest thing. The Web, by design, is decentralized. You don’t need permission to put up any kind of Web server or service. Social media should follow the decentralized path blazed by the Web and by the world’s oldest and most successful conversational app, namely email.
It seems painfully obvious that a network of thousands or millions of servers, independently operated, sizes ranging from tiny to huge, is inherently more flexible and resilient than having all the conversations owned and operated by one globally-centralized business empire.
To be decentralized, you need a protocol framework so the servers can talk to each other. CoSocial uses ActivityPub, which at the moment I think is the best choice.
Some smart people who like the Bluesky experience are trying to make its AT Protocol work in a way that’s as demonstrably decentralized as ActivityPub is today. Maybe they’ll succeed; then operations like CoSocial should maybe consider it as an alternative. We’ll see.
Not for profit
Our goals do not include enriching any investors. We plan to pay the people who do the work and have just advertised for our first paid position.
We’re not-for-profit because the goals of the investor community are incompatible with a healthy online experience. In 2025, companies are judged on profit growth; everything else is secondary. If you can grow your audience organically, good, but the world is finite, so when you’ve attracted everyone you’re going to, you’re going to have to focus on raising prices and reducing costs. Which is likely to produce an unpleasant experience for the people you serve.
Cory Doctorow aptly uses “enshittification” to describe this often-observed pattern.
A registered co-operative
There are a lot of different ways to set up a not-for-profit. The simplest organization is no organization: Someone buys a domain name, puts up a server, invites people on board, and uses Patreon donations to keep the lights on.
Which is exactly what Chad did at Mstdn.ca, and it seems to be working OK. It’s a testament to the strong fibres of the Web, still there after all these decades of corrupting big money, that you can just do this without asking anyone’s permission, and get away with it.
But we didn’t. We are a registered co-operative in BC, Canada’s westernmost province. It took us a couple of months to pull together the Board and constitution and bylaws. We have to file annual reports and comply with governing legislation.
I am absolutely not going to suggest that a cooperative is the optimal not-for-profit approach. But I am pretty convinced that if you want to be treated as an organic component of civil society, you should work within its frameworks. Plus, it seems to me, on the evidence, that member-owned cooperatives are a pretty great way to organize human activities.
More than a click to join
As I write this, most modern social-media products let you just roll up to the Web site and say “I wanna join”, and they say “click here”. Or even just make a couple of API calls.
We’re not like that. You have to apply for membership and offer a few words about why. Then you have to [*gasp*] pay. A big fifty Canadian dollars a year buys a co-op membership and a Fediverse account. The first year of Fediverse is $40 so we can book $10 of your initial payment as payment for a CoSocial share (refundable if you later cancel).
When you apply, we check that you did so from an IP address in Canada, we glance at your reasons for wanting to join, then if you haven’t already contributed, we send you an email asking you to pony up and, once you have, we let you in.
The whole thing takes maybe five minutes of effort from the new member and a CoSocial moderator.
What matters about this process? The fact that it exists. Nicole the Fediverse Chick can’t get a CoSocial account, nor can any other flavor of low-rent griefer or channer or MAGA chud. Just the fact that you can’t join by calling a few APIs filters out most of the problems, and then being asked to, you know, pay a little money, takes care of the rest.
Which is to say, being a CoSocial moderator is dead easy. Sure, we get reports on our members from time to time. So far, zero have been really worrying. On a small single-digit-number of times, we’ve asked a member to consider the fact that they seem to be irritating some people.
And we throw reports from Hasbara keyboard warriors and similarly non-credible sources on the floor.
The key take-away: Imposing just a little teeny-tiny bit of friction on the onboarding process seems to achieve troll-resistance in one easy step.
Transparent
We have a bank account and credit cards and so on, but we run all our finances through a nice service called OpenCollective. Which makes all our financial moves 100% transparent: Here they are.
No Advertising
CoSocial has none, and never will.
It is a repeating pattern that advertising-supported social-media products offered by for-profit enterprises become engulfed in a tempest of controversy and litigation.
Since it’s axiomatic that centralized social media has to be free to use, ads are required, which means the advertisers are the customers. Those customers will continuously agitate for more intrusive advertising capabilities and for brand protection by avoiding sex, activism, or anything that might make anyone uncomfortable.
I don’t know about you, but I’m interested in sex and activism.
Intellectually, I appreciate that advertising should be a normal facet of a functional economy. How else am I going to find out what’s for sale? But empirically, advertising as it’s done now seems to exert a powerfully corrupting influence.
The only way forward?
I’m not claiming that CoSocial is. But I am arguing strongly for the combination of decentralization, not-for-profit, legal registration, non-zero onboarding friction, transparency, and advertising rejection. There are lots of ways to shape resilient social-media products that do these things. There are other legally regulated non-profit structures that aren’t co-ops.
Also, there are plenty of other organizations that would benefit from hosting social-media voices: Government departments, academic institutions, sports teams, fan clubs, marketing groups, professional societies, videogame platforms, and, well, the list is long.
How’s CoSocial doing?
Slow and steady. We’re tiny, less than 200 strong, but we get a few new members every month. Two years in, a grand total of two members have decided not to renew.
We’ve got a modestly pleasing buildup of money in the bank account, which means that we need to get serious about becoming less volunteer-centric, and thus more resilient.
The service is fun to use, it’s reliable, and about as troll-free as can be. Come on in!
(But only if you’re in Canada and willing to pay a bit.)
Union of Finite Automata 28 Jul 2024, 7:00 pm
In building Quamina, I needed to compute the union of two finite automata (FAs). I remembered from some university course 100 years
ago that this was possible in theory, so I went looking for the algorithm, but was left unhappy.
The descriptions I found tended to be hyper-academic, loaded with mathematical notation that I found unhelpful, and
didn’t describe an approach that I thought a reasonable programmer would reasonably take. The purpose of this ongoing entry is to present a
programmer-friendly description of the problem and of the algorithm I adopted, with the hope that some future developer, facing
the same problem, will have a more satisfying search experience.
[Important update: There’s a serious error halfway through; see here.]
There is very little math in this discussion (a few subscripts), and no circles-and-arrows pictures. But it does have working Go code.
Finite automata?
I’m not going to rehash the theory of FAs (often called state machines). In practice the purpose of an FA is to match (or fail to match) some input against some pattern. What the software does when the input matches the pattern (or doesn’t) isn’t relevant to our discussion today. Usually the inputs are strings and the patterns are regular expressions or equivalent. In practice, you compile a pattern into an FA, and then you go through the input, character by character, trying to traverse the FA to find out whether it matches the input.
An FA has a bunch of states, and for each state there can be a list of input symbols that lead to transitions to other states. What exactly I mean by “input symbol” turns out to be interesting and affects your choice of algorithm, but let’s ignore that for now.
The following statements apply:
One state is designated as the “start state” because, well, that’s where you start.
Some states are called “final”, and reaching them means you’ve matched one or more patterns. In Quamina’s FAs, each state has an extra field (usually empty) saying “if you got here you matched P*, yay!”, where P* is a list of labels for the (possibly more than one) patterns you matched.
It is possible that you’re in a state and for some particular input, you transition to more than one other state. If this is true, your FA is nondeterministic, abbreviated NFA.
It is possible that a state can have one or more “epsilon transitions”, ones that you can just take any time, not requiring any particular input. (I wrote about this in Epsilon Love.) Once again, if this is true, you’ve got an NFA. If neither this statement nor the previous are true, it’s a deterministic finite automaton, DFA.
The discussion here works for NFAs, but lots of interesting problems can be solved with DFAs, which are simpler and faster, and this algorithm works there too.
Union?
If I have FA1 that matches “foo” and FA2 that matches “bar”, then their union,
FA1 ∪ FA2, matches both “foo”
and “bar”. In practice Quamina often computes the union of a large number of FAs, but it does so a pair at a time, so we’re
only going to worry about the union of two FAs.
The academic approach
There are plenty of Web pages and YouTubes covering this. Most of them are full of Greek characters and math symbols. They go like this:
You have two FAs, call them
AandB.Ahas statesA1, …AmaxA,BhasB1, …BmaxBThe union contains all the states in
A, all the states inB, and the “product” ofAandB, which is to say states you could callA1B1,A1B2,A2B1,A2B2, …AmaxABmaxB.For each state
AXBY, you work out its transitions by looking at the transitions of the two states being combined. For some input symbol, ifAXhas a transition toAXXbutBYhas no transition, then the combined state just has the A transition. The reverse for an input whereBYhas a transition butAXdoesn’t. And ifAXtransitions toAXXandBYtransitions toBYY, then the transition is toAXXBYY.Now you’ll have a lot of states, and it usually turns out that many of them aren’t reachable. But there are plenty of algorithms to filter those out. You’re done, you’ve computed the union and
A1B1is its start state!
Programmer-think
If you’re like me, the idea of computing all the states, then throwing out the unreachable ones, feels wrong. So here’s what I suggest, and has worked well in practice for Quamina:
First, merge
A1andB1to make your new start stateA1B1. Here’s how:If an input symbol causes no transitions in either
A1orB1, it also doesn’t cause any inA1B1.If an input symbol causes a transition in
A1toAXbut no transition inB1, then you adoptAXinto the union, and any otherAstates it points to, and any they point to, and so on.And of course if
B1has a transition toBYbutA1doesn’t transition, you flip it the other way, adoptingBYand its descendents.And if
A1transitions toAXandB1transitions toBY, then you adopt a new stateAXBY, which you compute recursively the way you just did forA1B1. So you’ll never compute anything that’s not reachable.
I could stop there. I think that’s enough for a competent developers to get the idea? But it turns out there are a few details, some of them interesting. So, let’s dig in.
“Input symbol”?
The academic discussion of FAs is very abstract on this subject, which is fair enough, because when you’re talking about how to build, or traverse, or compute the union of FAs, the algorithm doesn’t depend very much on what the symbols actually are. But when you’re writing code, it turns out to matter a lot.
In practice, I’ve done a lot of work with FAs over the years, and I’ve only ever seen four things used as input symbols to drive them. They are:
Unicode “characters” represented by code points, integers in the range 0…1,114,111 inclusive.
UTF-8 bytes, which have values in the range 0…244 inclusive.
UTF-16 values, unsigned 16-bit integers. I’ve only ever seen this used in Java programs because that’s what its native
chartype is. You probably don’t want to do this.Enum values, small integers with names, which tend to come in small collections.
As I said, this is all I’ve seen, but 100% of the FAs that I’ve seen automatically generated and subject to set-arithmetic operations like Union are based on UTF-8. And that’s what Quamina uses, so that’s what I’m going to use in the rest of this discussion.
Code starts here
This comes from Quamina’s
nfa.go. We’re going to look at the function
mergeFAStates, which implements the merge-two-states logic described above.
Lesson: This process can lead to a lot of wasteful work. Particularly if either or both of the states transition on ranges of
values like 0…9 or a…z. So we only want to do the work merging any pair of states once, and we want
there only to be one merged value. Thus we start with a straightforward memo-ization.
func mergeFAStates(state1, state2 *faState, keyMemo map[faStepKey]*faState) *faState { // try to memo-ize mKey := faStepKey{state1, state2} combined, ok := keyMemo[mKey] if ok { return combined }
Now some housekeeping. Remember, I noted above that any state might contain a signal saying that arriving here
means you’ve matched pattern(s). This is called fieldTransitions, and the merged state obviously has to
match all the things that either of the merged states match. Of course, in the vast majority of cases neither merged state
matched anything and so this is a no-op.
fieldTransitions := append(state1.fieldTransitions, state2.fieldTransitions...)
Since our memo-ization attempt came up empty, we have to allocate an empty structure for the new merged state, and add it to the memo-izer.
combined = &faState{table: newSmallTable(), fieldTransitions: fieldTransitions} keyMemo[mKey] = combined
Here’s where it gets interesting. The algorithm talks about looking at the inputs that cause transitions in the states we’re merging. How do you find them? Well, in the case where you’re transitioning on UTF-8 bytes, since there are only 244 values, why not do the simplest thing that could possibly work and just check each byte value?
Every Quamina state contains a table that encodes the byte transitions, which operates like the Go construct
map[byte]state. Those tables are implemented in
a compact data structure optimized for fast traversal. But for doing this
kind of work, it’s easy to “unpack” them into a fixed-sized table; in Go, [244]state. Let’s do that for the states
we’re merging and for the new table we’re building.
u1 := unpackTable(state1.table) u2 := unpackTable(state2.table) var uComb unpackedTable
uComb is where we’ll fill in the merged transitions.
Now we’ll run through all the possible input values; i is the byte value, next1 and next2
are the transitions on that value. In practice, next1 and next2 are going to be null most of the time.
for i, next1 := range u1 { next2 := u2[i]
Here’s where we start building up the new transitions in the unpacked array uComb.
For many values of i, you can avoid actually merging the states to create a new one. If the transition is the
same in both input FAs, or if either of them are null, or if the transitions for this value of i are the same as
for the last value. This is all about avoiding unnecessary work and the switch/case structure is the
result of a bunch of profiling and optimization.
switch { case next1 == next2: // no need to merge uComb[i] = next1 case next2 == nil: // u1 must be non-nil uComb[i] = next1 case next1 == nil: // u2 must be non-nil uComb[i] = next2 case i > 0 && next1 == u1[i-1] && next2 == u2[i-1]: // dupe of previous step - happens a lot uComb[i] = uComb[i-1]
If none of these work, we haven’t been able to avoid merging the two states. We do that by a recursive call to invoke all the logic we just discussed.
There is a complication. The automaton might be nondeterministic, which means that there might be more than one transition
for some byte value. So the data structure actually behaves like map[byte]*faNext, where faNext is a
wrapper for a list of states you can transition to.
So here we’ve got a nested loop to recurse for each possible combination of transitioned-to states that can occur on this byte value. In a high proportion of cases the FA is deterministic, so there’s only one state from each FA being merged and this nested loop collapses to a single recursive call.
default: // have to recurse & merge var comboNext []*faState for _, nextStep1 := range next1.states { for _, nextStep2 := range next2.states { comboNext = append(comboNext, mergeFAStates(nextStep1, nextStep2, keyMemo)) } } uComb[i] = &faNext{states: comboNext} } }
We’ve filled up the unpacked state-transition table, so we’re almost done. First, we have to compress it into its optimized-for-traversal form.
combined.table.pack(&uComb)
Remember, if the FA is nondeterministic, each state can have “epsilon” transitions which you can follow any time without requiring any particular input. The merged state needs to contain all the epsilon transitions from each input state.
combined.table.epsilon = append(state1.table.epsilon, state2.table.epsilon...) return combined }
And, we’re done. I mean, we are once all those recursive calls have finished crawling through the states being merged.
Oops
The discussion of epsilons above is wrong, in a way that’s harder to reproduce than you might think.
The discussion is still
correct for DFA’s and (weirdly) (I think) (not sure why yet) the shell-style “wildcard” * operator, which means
.* in a regular expression.
It’s not clear that in general there’s a way to merge (Quamina-style) two NFA states when either or both of them have epsilon transitions. Per the academic literature, the right way to get the union of two NFAs is to have an empty branch state with two epsilon transitions, one to each NFA. So you traverse the two in parallel.
It took me a a whole lot of pain to figure this out and I haven’t entirely worked out the best implementation. I promise more regular-expressions-at-scale walls of text and code in this space when I do.
I write this because when you type “merge nondeterministic finite automata” into Web search, the blog you are now reading is dangerously high in the search results.
Is that efficient?
As I said above, this is an example of a “simplest thing that could possibly work” design. Both the recursion and the unpack/pack sequence are kind of code smells, suggesting that this could be a pool of performance quicksand.
But apparently not. I ran a benchmark where I added 4,000 patterns synthesized from the Wordle word-list; each of them looked like this:
{"allis": { "biggy": [ "ceils", "daisy", "elpee", "fumet", "junta", … (195 more).
This produced a huge deterministic FA with about 4.4 million states, with the addition of these hideous worst-case patterns running at 500/second. Good enough for rock ’n’ roll.
How about nondeterministic FAs? I went back to that Wordle source and, for each of its 12,959 words, added a pattern with a random wildcard; here are three of them:
{"x": [ {"shellstyle": "f*ouls" } ] }
{"x": [ {"shellstyle": "pa*sta" } ] }
{"x": [ {"shellstyle": "utter*" } ] }
This produced an NFA with 46K states, the addition process ran at 70K patterns/second.
Sometimes the simplest thing that could possibly work, works.
Page processed in 0.04 seconds.
Powered by SimplePie 1.4-dev, Build 20170403172323. Run the SimplePie Compatibility Test. SimplePie is © 2004–2025, Ryan Parman and Geoffrey Sneddon, and licensed under the BSD License.